
Machine Learning Parkinson's Disease Detection Model
5/29/20243 min read
Parkinson's disease, a progressive neurological disorder that primarily affects motor function due to the loss of dopamine-producing brain cells. An early detection of this is beneficial to the patient since early and accurate diagnosis can significantly affect treatment outcomes, allowing patients to begin therapeutic interventions sooner. Early treatment can slow the progression of the disease, improve quality of life, and extend motor function. Now I will delve deeper into my ML project that revolves around using ML techniques to accurately predict if the patient has Parkinson's disease or not.
GitHub link(dataset also included): https://github.com/JohnsonLiu556/Parkinsons-Disease-ML-Prediction/tree/main
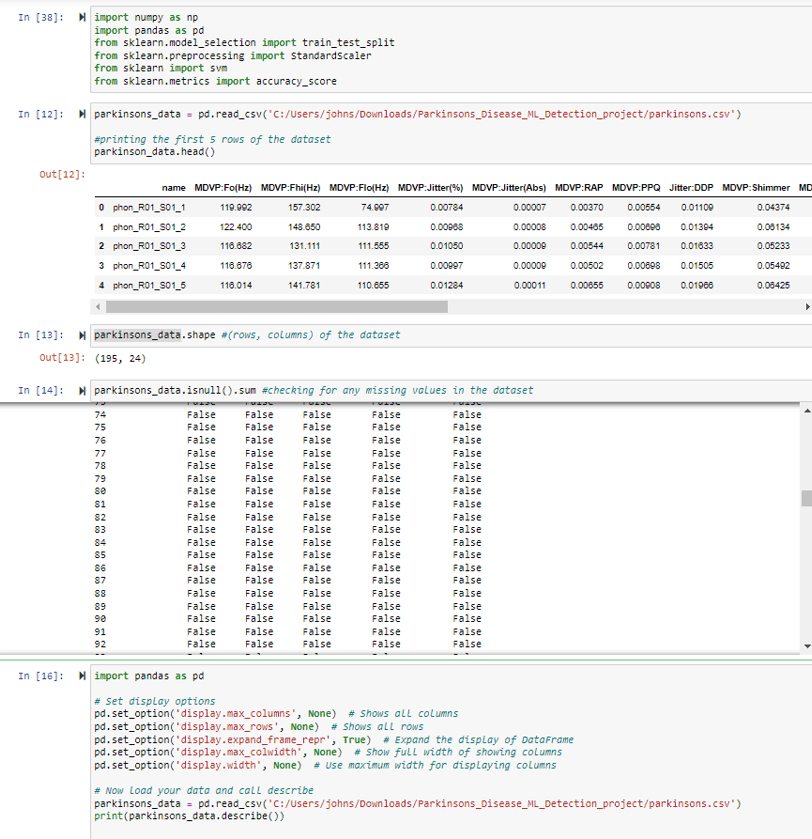
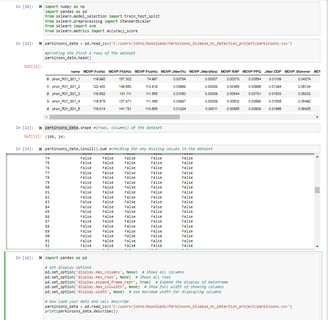
This is where I did the initial data reading/loading, where I imported important Python libraries such as NumPy, pandas, sklearn's train_test_split, StandardScaler, and accuracy_score. The dataset in this case is being read from a CSV file using pandas and just for a sanity check, I asked it to print out the first 5 rows. The rest of the code in the image is more for sanity check and ensuring that I do not work with the wrong type of data.
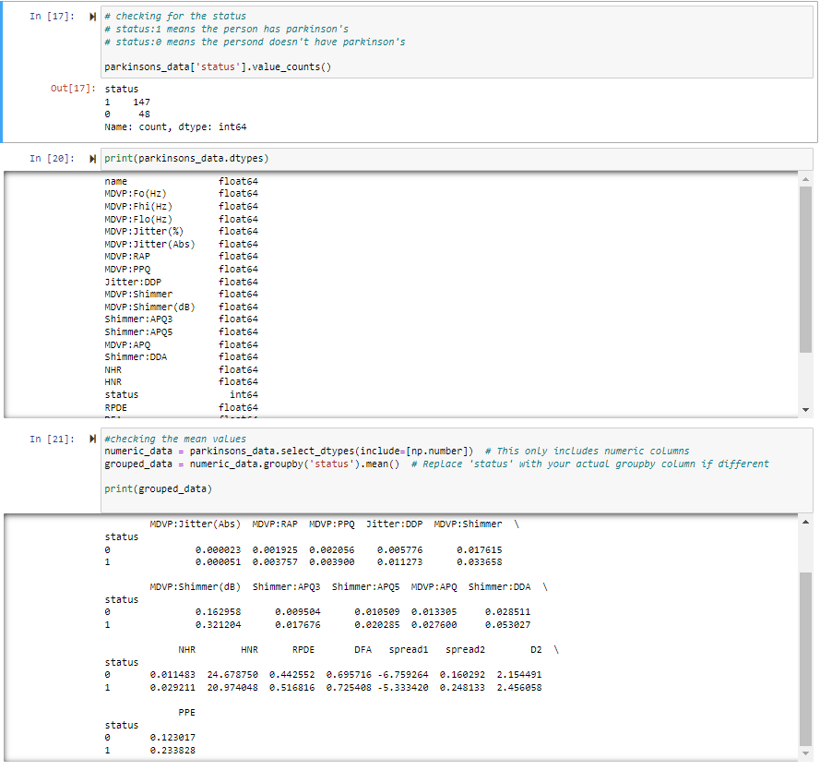
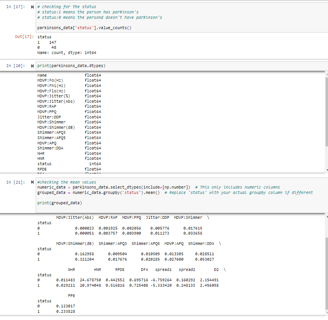
In this section, I did more statistical summaries for the dataset where I try to understand the distributions of various features
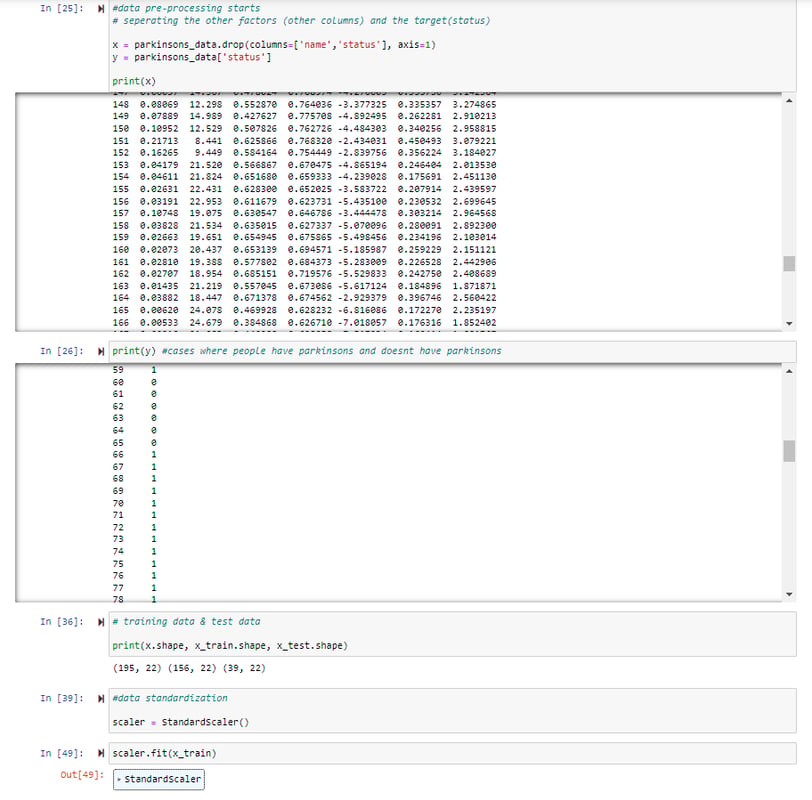
Features and the target variable ('status') are separated into "x" and "y". Note that when it says "status: 1", it means the patient has Parkinson's disease, vice versa. Features are standardized using "StandardScaler" to ensure the model receives data without bias due to the scale of features.
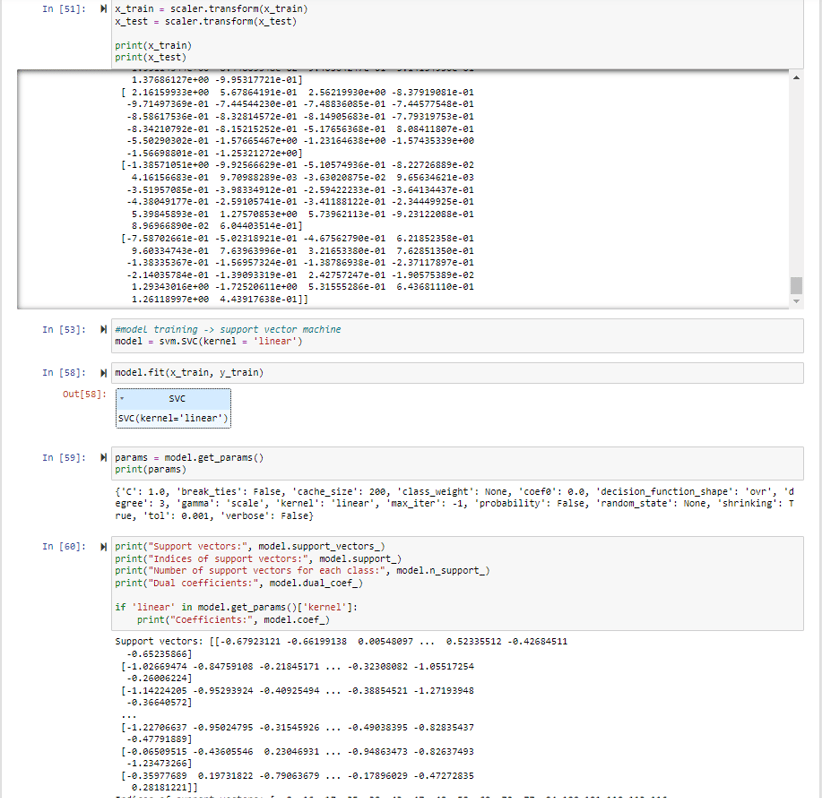
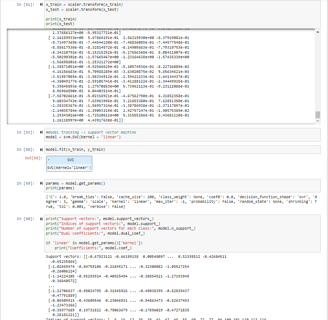
Here, an SVM with a linear kernel is chosen as the model to predict the status of Parkinson’s Disease and the model is trained on the training set split from the dataset.
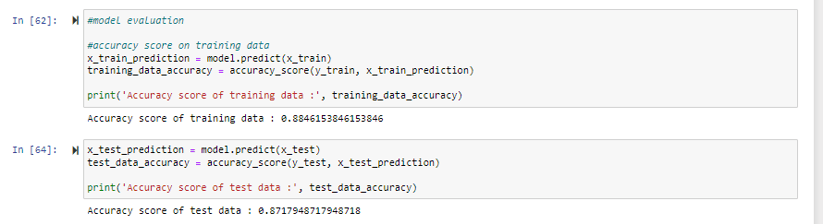
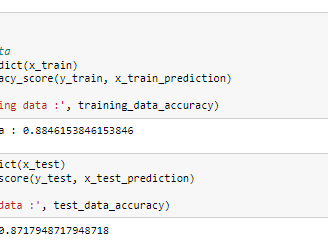
The model's accuracy is assessed on the training set and the model’s performance is validated on the test set to ensure it generalizes well to new data. Notice that the accuracy of the training data is ~88% and the accuracy of the test data is ~87%, this means that there is no overfitting or underfitting in this case so this is a reliable model.
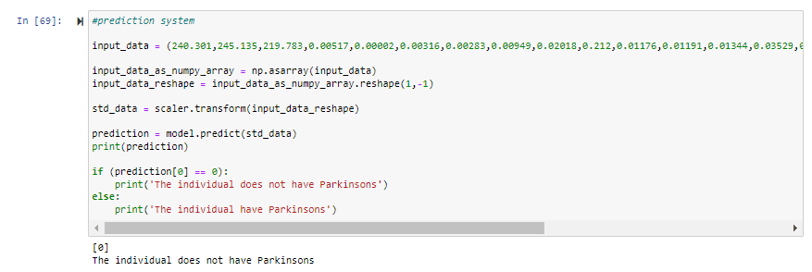
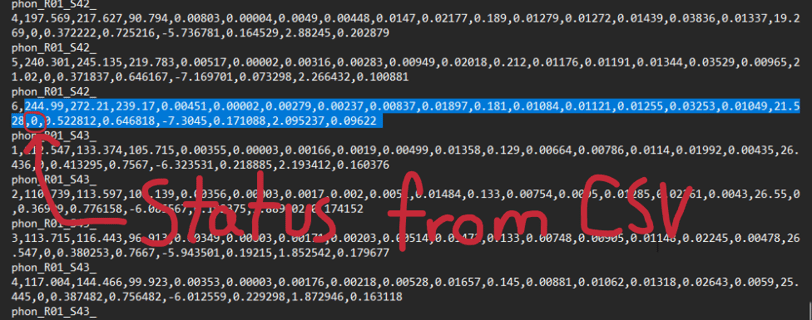
The part of model is used to predict Parkinson's Disease status on new data points. Input data is scaled using the same scaler fitted on the training data and then fed into the model for prediction. I've basically copied the parameters from the CSV file to test it (make sure to delete the status parameter in this section or else it will not work) and the results from the model matches from the results from the CSV file.
Contact Information
jl3486@cornell.edu
johnsonliu556@gmail.com